Meet YubiBERT, an open source fintech desi language model
NLP models have a number of use cases in fintech, such as when a bank wants to automate its chatbot to perform basic banking services, or wants to automate document collection processes with a bot. Yubi decided to create a large language model (LLM) that had the ability to understand 13 Indian languages, and they did all this from scratch, with the idea of giving it away as an open source gift to the rest of the busybodies , the desi fintech industry.
The entire model, called YubiBERTwas built by a single engineer, Swapnil Ashok Jadhavdirector of data science at Yubi.
Jadhav says collecting enough raw data to train the language model was one of the most difficult parts of the project. He had to scrape data from the web for a month to get around 300 GB of data. This was then cleared up to around 220 GB. The biggest chunk of data, says Swapnil, came from news websites. “We recognized several sites with different languages plus English, we scraped all those sites that were fintech related. We brought in conversations that happen in the comments section under the news where people generally talk or complain. We also included Wikipedia because we also wanted to cover words which is known to everyone, he says.
Jadhav says the code uses the NLP architecture RoBERTa, which was trained by Facebook two years ago. But they minimized the model to suit Yubi’s needs.
“We don’t work for any other domains. So we found that we don’t need such a big model. We also wanted to run this model faster on CPU servers because GPU costs are very high. In the end, our model was a third or a quarter of the model Facebook created.”
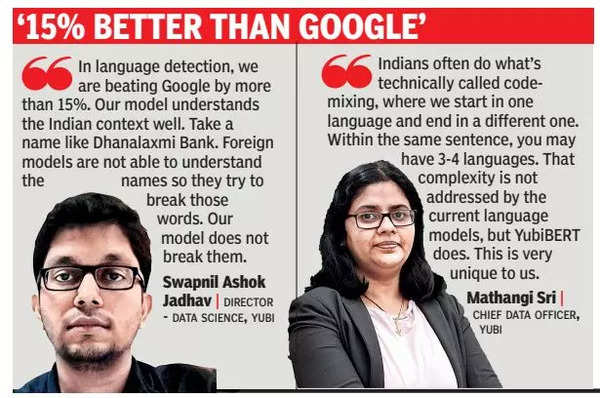
Mathangi Sri, chief data officer at Yubi, says language detection was one of the core problems they were trying to solve. “Indians can start speaking English, go to Hindi and come back to English, so language recognition is very important. And YubiBERT does it excellently, she says.
Google and a couple of others, Sri says, have pretty good language modeling packages that do a decent job of language detection, but YubiBERT beats them all.


